
Back in 2017, Ben Silbermann, CEO of Pinterest, stated that “a lot of the future of search is going to be about pictures instead of keywords”. Certainly, advances in visual search from the likes of Google, Pinterest, Bing and ASOS are aiming to make it quick and easy to, for example, snap a picture and buy whatever’s been captured, or see similar items. Of course, the ability for users to take a picture of something they like and immediately be given the option to buy it represents an exciting potential revenue stream for ecommerce sites.
What is visual search?
It’s worth noting that visual search is distinct from image search. Image search is the traditional method of searching for images, with a text based query returning an image result. Even this technology has improved considerably over the years, with much more relevant images being returned as results.
Visual search aims to emulate the same biases people use when we see and recognise items, so the process is much more complex than relatively simple text-based image searches. With visual searches, the image is the query, and rather than just identifying the image, search engines understand it.
This search technology is still going through a lot of research and development. We’re still understanding how humans identify and understand what they see, so understandably, teaching a machine to do the same is incredibly complex. That being said, some impressive inroads are being made. Let’s look at a few examples:
Bing visual search
Bing’s visual search feature, launched in 2017, allows users to search within images and be presented with related objects. This is not to be confused with an earlier Bing feature launched in 2009, also called Bing Visual Search.
For example, a search for “living room decorating ideas” returns this image:

Hovering in the top right corner gives me the option to visual search:

Using this, I can hone in on something I like the look of:

And in this case, I’m given a lot of related product images:

Where shopping intent is detected behind a visual search query, Bing will also give you related products with price information, and you’ll be taken directly to the merchant after clicking on them.
However, having played around with this feature quite a lot, I’ve not yet been given this option to buy the item I’ve selected. Using Bing’s example, it would look like the following:
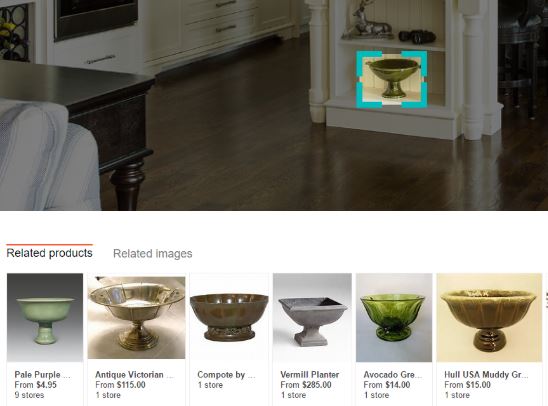
Overall, it doesn’t yet seem to be working perfectly. Often it can fail to recognise the item you’ve selected and return something that’s the same colour, but a completely different object. Still, it can only improve from here!
Google Lens
Google Lens, following a big update at the end of May 2018, aims to make your smartphone camera act like a visual browser. It will offer real time object recognition, and this update is designed to emphasise the shopping side of visual search.
Conveniently, this new version of Google Lens is going to be built directly into a number of Android smartphone cameras, meaning it doesn’t need to be opened in a separate app like the old version of Lens did.
It’ll also have a ‘Style Match’ feature, similar to Pinterest Lens, and in line with the other big players in visual search, the emphasis on shopping will give users a link to buy what they’ve snapped or browse related items.
Currently in beta mode, it’ll be interesting to see how well this updated Google Lens works in comparison to competitor offerings.
Pinterest visual search
Pinterest is aiming to establish itself as the leader in visual search, and several recent hires were ex-Google senior image search engineers, including Google’s Head of Image Search. Arguably at this stage, Pinterest is winning the race, offering probably the most useful and advanced visual search tool currently available.
Pinterest Lens, launched in 2017, has several cool visual search functionalities. The one I find most impressive is the “Lens Your Look” feature. With this, you could take a picture of a denim jacket, and it’ll give you an idea of what you could wear with it – a great example of how visual search engines understand images, as opposed to just identifying them.
Additionally, it has a similar shopping functionality to Bing’s visual search. If you see someone wearing something you like the look of, in theory you’re able to take a picture using Pinterest Lens and it will return Pins allowing you to shop the look. Through a partnership with ShopStyle, millions of shoppable products across tens of thousands of brands are being linked to Pins, and it’s a simple case of clicking a link within Pins to be able to buy the item you like.
I tried this out myself and found that it worked quite well.
First of all, I took a picture of this rucksack using the Pinterest app:

It managed to recognise that it’s a black backpack, and gave me some items matching the style:
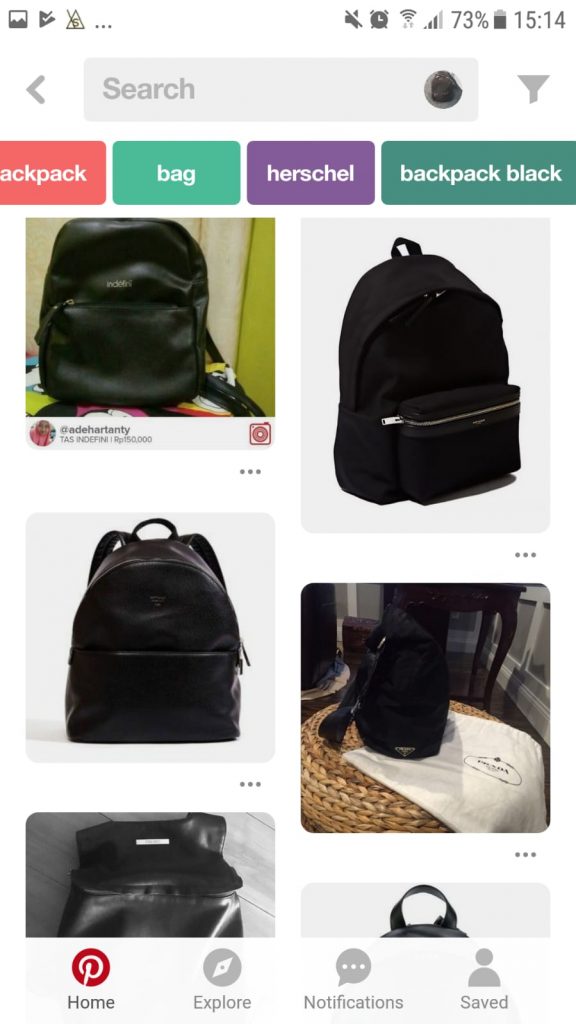
I was able to browse through these, and although a lot of items didn’t have the shopping functionality, pretty quickly I was able to find one that had the option to buy direct from the merchant.
Pinterest Lens isn’t just used for fashion-based searches, either – according to Pinterest’s search trend data, the top categories for Lens searches include fashion, home décor, art and food. Top trending Lens searches include things as varied as wedding dresses, quilts, plants and – of course – cats.
In March 2018, ASOS globally rolled out a similar Style Match feature on iOS and Android. Whereas Pinterest returns Pins from any number of different brands, the ASOS visual search functionality returns products from the ASOS product range.
Get a copy of our Visual Search and Voice Search white paper
Download the Voice and Visual Whitepaper
Download the Voice and Visual Whitepaper
What are the implications of visual search?
Digital marketers should start considering this technology. Pinterest Lens returns only Pinterest Pins, so without a Pinterest presence, you’re not going to be seen here. There are 200 million active users and 600 million Pinterest Lens searches every month, a figure which has seen sustained growth since the technology was released. 87% of Pinterest users report that Pinterest helped them decide what to buy.
That’s not too surprising when we consider that Pinterest users are likely to have high buying intent, as they’re in planning mode, looking for inspiration and ready to buy. Visual searches made on any platform are likely to be low in the funnel, too. Users have seen a specific item they like and are looking for more information or the opportunity to buy. Rather than making a text search for “men’s shirts”, a user could be taking a picture of an exact one they like, and looking to buy.
There are a number of things you can do to help ready your images for a visual search future, most of which are SEO best practice anyway.
- Mark up your product images using schema to help search engines understand attributes such as currency, price, item name and URL.
- Images should be properly optimised, which will also help improve your page load speed. Check out this thorough guide on how to optimise images for some recommendations.
- And of course, visual search is solely mobile – you can’t take pictures on your desktop computer. So, as it should be anyway, ensure your site is fully mobile responsive and that mobile is a primary consideration in your digital strategy.
With millions already using Pinterest Lens and as machine learning technology continues to improve, it’s becoming easier to envision a future in which it’s very convenient for users – at least within certain industries – to search for a product by image. In this way, visual search is an exciting opportunity for ecommerce sites to generate additional traffic and revenue.
For more information on visual search, or for help with your SEO strategy, get in touch with us today.




