What is pagination and why is it important?
Pagination is when content has been divided between a series of pages, such as on ecommerce category pages or lists of blog articles.
Pagination is one of the ways in which page equity flows through a website.
It’s crucial for SEO that it’s done correctly. This is because the pagination setup will impact how effectively crawlers can crawl and index both the paginated pages themselves, and all the links on those pages like the aforementioned product pages and blog listings.
What are the potential SEO issues with pagination?
I’ve come across a few blogs which explain that pagination is bad and that we should block Google from crawling and indexing paginated pages, in the name of either avoiding duplicate content or improving crawl budget.
This isn’t quite correct.
Duplicate content
Duplicate content isn’t an issue with pagination, because paginated pages will contain different content to the other pages in the sequence.
For example, page two will list a different set of products or blogs to page one.
If you have some copy on your category page, I’d suggest only having it on the first page and removing it from deeper pages in the sequence. This will help signal to crawlers which page we want to prioritise.
Don’t worry about duplicate meta descriptions on paginated pages either – meta descriptions are not a ranking signal, and Google tends to rewrite them a lot of the time anyway.
Crawl budget
Crawl budget isn’t something most sites have to worry about.
Unless your site has millions of pages or is frequently update – like a news publisher or job listing site – you’re unlikely to see serious issues arise relating to crawl budget.
If crawl budget is a concern, then optimising to reduce crawling to paginated URLs could be a consideration, but this won’t be the norm.
So, what is the best approach? Generally speaking, it’s more valuable to have your paginated content crawled and indexed than not.
This is because if we discourage Google from crawling and indexing paginated URLs, we also discourage it from accessing the links within those paginated URLs.
This can make URLs on those deeper paginated pages, whether those are products or blog articles, harder for crawlers to access and cause them to potentially be deindexed.
After all, internal linking is a crucial component of SEO and essential in allowing users and search engines to find our content.
So, what is the best approach for pagination?
Assuming we want paginated URLs and the content on those pages to be crawled and indexed, there’s a few key points to follow:
- Href anchor links should be used to link between multiple pages. Google doesn’t scroll or click, which can lead to problems with “load more” functionality or infinite scroll implementations
- Each page should have a unique URL, such as category/page-2, category/page-3 etc.
- Each page in the sequence should have a self-referencing canonical. On /category/page-2, the canonical tag should point to /category/page-2.
- All pagination URLs should be indexable. Do not use a noindex tag on them. This ensures that search engines can crawl and index your paginated URLs and, more importantly, makes it easier for them to find the products that sit on those URLs.
- Rel=next/prev markup was used to highlight the relationship between paginated pages, but Google said they stopped supporting this in 2019. If you’re already using rel=next/prev markup, leave it in place, but I wouldn’t worry about implementing it if it’s not present.
As well as linking to the next couple of pages in the sequence, it’s also a good idea to link to the final page in your pagination. This gives Googlebot a nice link to the deepest page in the sequence, reducing click depth and allowing it to be crawled more effectively. This is the approach taken on the Hallam blog:
- Ensure the default sorting option on a category page of products is by best selling or your preferred priority order. We want to avoid our best-selling products being listed on deep pages, as this can harm their organic performance.
You may see paginated URLs start to rank in search when ideally you want the main page ranking, as the main page is likely to deliver a better user experience (UX) and contain better content or products.
You can help avoid this by making it super clear which the ‘priority’ page is, by ‘de-optimising’ the paginated pages:
- Only have category page content on the first page in the sequence
- Have meta titles dynamically include the page number at the start of the tag
- Include the page number in the H1
Common pagination mistakes
Don’t be caught out by these two common pagination mistakes!
- Canonicalising back to the root page
This is probably the most common one, whereby /page-2 would have a canonical tag back to /page-1. This generally isn’t a good idea, as it suggests to Googlebot not to crawl the paginated page (in this case page 2), meaning that we make it harder for Google to crawl all the product URLs listed on that paginated page too. - Noindexing paginated URLs
Similar to the above point, this leads search engines to ignore any ranking signals from the URLs you’ve applied a noindex tag to.
What other pagination options are there?
‘Read more’
This is when a user reaches the bottom of a category page and clicks to load more products.
There’s a few things you need to be careful about here. Google only crawls href links, so as long as clicking the load more button still uses crawlable links and a new URL is loaded, there’s no issue.
This is the current setup on Asos. A ‘load more’ button is used, but hovering over the button we can see it’s but it’s an href link, a new URL loads and that URL has a self referencing canonical: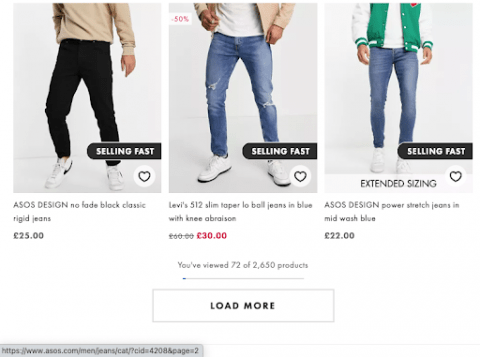
If your ‘load more’ button only works with Javascript, with no crawlable links and no new URL for paginated pages, that’s potentially risky as Google may not crawl the content hidden behind the load more button.
Infinite scroll
This occurs when users scroll to the bottom of a category page and more products automatically load.
I don’t actually think this is great for UX. There’s no understanding of how many products are left in the series, and users who want to access the footer can be left frustrated.
In my quest for a pair of men’s jeans, I found this implementation on Asda’s jeans range on their George subdomain at https://direct.asda.com/.
If you scroll down any of their category pages, you’ll notice that as more products are loaded, the URL does not change.
Instead, it’s fully reliant on Javascript. Without those href links, this is going to make it trickier for Googlebot to crawl all of the products listed deeper than the first page.
With both ‘load more’ and infinite scroll, a quick way to understand whether Javascript might be causing issues involving accessing paginated content is to disable Javascript.
In Chrome, that’s Option + Command + I to open up dev tools, then Command + Shift + P to run a command, then type disable javascript: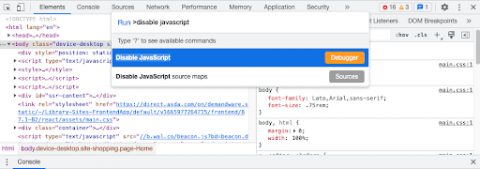
Have a click around with Javascript disabled and see if the pagination still works.
If not, there could be some scope for optimisation. In the examples above, Asos still worked fine, whereas George was fully reliant on JS and unable to use it without it.
Conclusion
When handled incorrectly, pagination can limit the visibility of your website’s content. Avoid this happening by:
- Building your pagination with crawlable href links that effectively link to the deeper pages
- Ensuring that only the first page in the sequence is optimised by removing any ‘SEO content’ from paginated URLs, and insert the page number in title tags.
- Remember that Googlebot doesn’t scroll or click, so if a Javascript-reliant load more or infinite scroll approach is used, ensure it’s made search-friendly, with paginated pages still accessible with Javascript disabled.
I hope you found this guide on pagination useful, but if you need any further advice or have any questions, please don’t hesitate to reach out to me on LinkedIn or contact a member of our team.