When it comes to Search Engine Optimisation (SEO), duplicate content is a term that can strike fear into the hearts of website owners and content creators as it can confuse search engines on which version of a page it should rank. This could then have a negative effect on the visibility of both URLs, leading to lower organic visibility and fewer clicks from potential visitors.
But what exactly is duplicate content, and why is it such a concern for SEO? In this blog, we’ll explore:
- What duplicate content is
- What causes duplicate content
- How to identify duplicate content
- Implications of duplicate content
- How to fix/avoid duplicate content
Whether you’re a website owner, content creator, or just interested in SEO best practices, understanding duplicate content is essential to achieving your goals online.
What is duplicate content?
In a nutshell, duplicate content is when the same content appears in more than one location, whether that’s on the same website or another website. This is more or less exact duplicate content, but there are a few other types including:
- Near-duplicate content – content that is very similar to another page, but not an exact copy, which can occur when content is spun, rephrased or when two different versions of the same article are created
- Scraped content – content that is taken from another website without permission or attribution
- Syndicated content – this is content that is distributed to multiple websites, such as press releases or articles
Whilst there is no such thing as a “duplicate content penalty”, it can still negatively impact your rankings as search engines find it difficult to understand which page is more relevant to a searcher’s query. More than one page can therefore compete and rank for the same keyword, which is known as keyword cannibalisation and either drop in rankings or not rank at all!

One question that a lot of clients ask me is whether there’s any level of duplication that’s okay to have on your website. Technically, there’s no official limit on how much duplicate content you can have before it starts impacting rankings, plus there may be some cases where duplicate content can naturally happen without you realising.
However, if you’re already considering duplicating content in the first place in order to save time writing product descriptions for example, it sounds like you might not be doing the #1 thing that is best for your users and search engines: creating unique, helpful and authentic content.
As long as you do this, then you won’t have any problems, which is why it’s important to understand what duplicate content is, what causes it and how to fix and avoid it in order to maximise your chances of being ranked on search engines.
Why is duplicate content bad for SEO?
Duplicate content can cause quite a few issues, first and foremost for users as well as search engines and site owners.
- Impacts user experience – it can be frustrating for searchers if they are faced with the same content in different places and unable to find the right information quickly
- Damages trust – searchers won’t know which source to trust if duplicate is found in several pages
- Confuses search engines – if search engines crawl duplicate content on different pages, they won’t know which the best version is for a specific query
- Lowers rankings – search engines might rank the wrong version, pushing the original down or not at all
- Dilutes link profile – websites, whether your own or another, have to choose which page to link to. Instead of linking to one master version, websites will link to duplicate pages, thinly spreading link equity
Add all of these implications together and site owners will be faced with a loss in rankings and overall visibility, negatively impacting organic traffic levels and therefore potentially leads, sales and revenue.
This only stresses the importance of keeping your website and its content completely unique, trustworthy and genuinely helpful for both users and search engines.
Causes of duplicate content
According to experts at Google, 60% of the internet is duplicate and so this indicates that in most cases, website owners don’t intentionally create and use duplicate content. A lot of the time, we’re not aware that we have a lot of duplicate content on our websites and it can be down to technical mishaps.
1. Session IDs
Session IDs are unique identifiers that are generated to track a user’s unique session and are used to maintain the state of a user’s interaction with a website, such as adding products to your basket or pages visited during a session.
These session IDs are often included in URLs as a query parameter, such as ?sessionid=12345. These can cause duplicate content issues, because they generate unique URLs for each user session.
For example, if a user visits a product page on an e-commerce website, the session ID is added to the URL to track the user’s interaction. If another user visits the same product page, they will be assigned a different session ID, resulting in a unique URL for their session.
This creates multiple URLs for the same product page, which can be seen as duplicate content by search engines.
To avoid duplicate content issues caused by session IDs, you can use canonical tags to indicate the preferred URL for search engines to index or block those URLs in your website’s robots.txt file, both of which I’ll go through in more detail later.
2. URL tracking parameters
Also known as query parameters or URL parameters, these are additional pieces of information added to a URL that allow tracking and analysis of user behaviour. They typically appear after a question mark in the URL and consist of other special characters, such as =s and &s.
For example, in the URL https://example.com/page?source=google&campaign=adwords, source=google and campaign=adwords are URL tracking parameters that provide information about the source and campaign of the user’s visit to the page.
So if you have two of these URLs that point to the same page, but have different tracking parameters, search engines see these as two unique URLs, but of course, they will have the same content, hence why this can cause duplicate content issues.
3. Faceted navigation/filter URLs
Another case of URL variations can be found on e-commerce websites when you have a load of product or category pages, but the products themselves can have different characteristics, such as colour and size, which customers can select using a faceted navigation and filters.
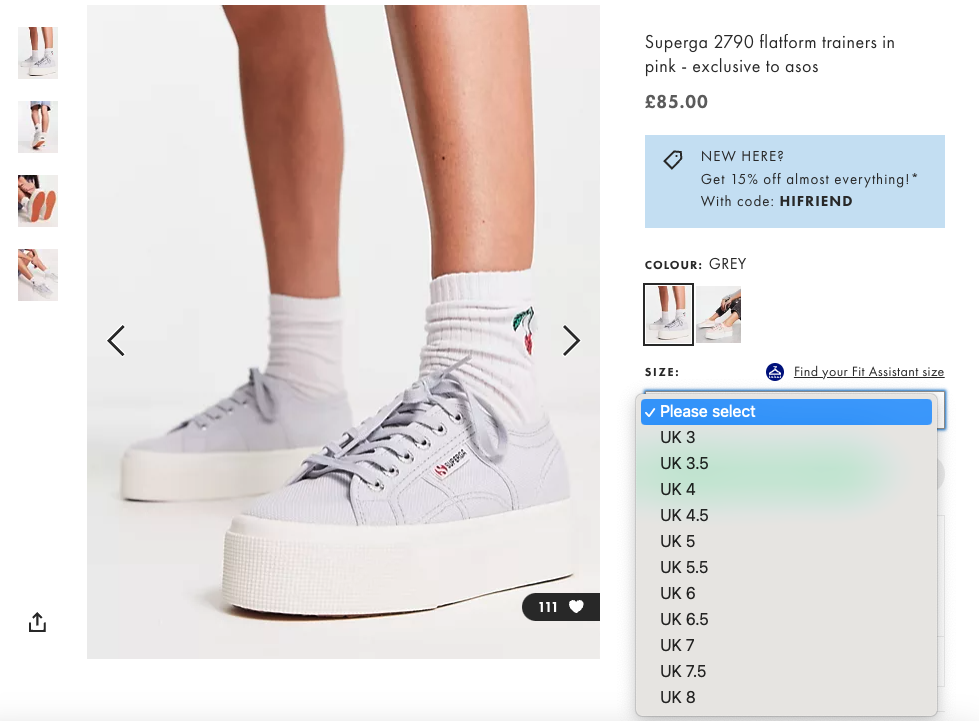
However, the problem with this is that each product variation can create a unique URL.
With every permutation of colour, size and other options, especially on a large e-commerce site like Asos, you could end up with hundreds of versions of the same product page that all have the same, duplicate content. Multiplying that across every product URL and duplicate content can start causing problems.
4. Pagination
Pagination is when you divide a long list or set of content into separate pages or sections, each containing a specific number of items. For example, an e-commerce website might use pagination to display products, with each page showing 20 items.
Pagination can cause duplicate content on a website when the same content appears on multiple pages with different URLs. This occurs because search engines may view each page as a separate piece of content, even if the content itself is identical or very similar.
For example, if an e-commerce website has a category page that lists 100 products, and these products are divided into five pages of 20 products each, each page will have its own unique URL. If the content on each of these pages is largely the same, search engines may view this as duplicate content.
5. Other URL variations
There are quite a few instances where other URL variations can happen such as:
- www. and non-www. – sometimes both versions of a URL will be accessible that have the same content
- Trailing slash and non-trailing slash – if your URLs are available with and without a trailing slash and are not resolved with a canonical or redirect, you’ve got a duplicate content problem
- http and https – again, sometimes insecure and secure URLs exist or when a website becomes secure, the insecure version is never redirected
- Printer-friendly pages – quite an old-school approach, but every so often we see some CMSs creating printer-friendly URLs which can sometimes be accidentally indexed. These contain the same content as their normal counterpart
If not properly resolved, combinations of the above can produce a large number of duplicate pages. For example:
- https://www.example.com/
- https://example.com
- https://example.com
- https://example.com/
- https://www.example.com
- http://www.example.com/
That’s six versions of exactly the same page, displaying exactly the same content!
This is resolved by ensuring 301 redirects are in place to your preferred canonical version of the URL.
For example, if https://www.example.com/ was the canonical URL, we would 301 redirect the non-www, non-trailing slash and non-http versions to https://www.example.com/.
6. Scraped content
Again, not always the website owner’s fault, but sometimes your content is duplicated by scrapers and published on another site without your consent, which you unfortunately can’t control.
What would help here is that the website could link back to your content, suggesting to search engines that yours is the original that should be ranked first, but the likelihood of that happening is somewhat slim.
7. Use of manufacturer product descriptions
Ecommerce retailers selling products from other manufacturers often use the stock manufacturer product copy on their product pages.
This doesn’t pose a huge problem and you won’t be penalised for using stock descriptions in your product page content, if the rest of your website is not duplicated.
However, we’ve found that it can be beneficial for SEO to create unique product copy that focuses on providing valuable and helpful information to the user.
On large sites this may not be feasible to roll out at scale, but you could start with your priority SEO pages and roll out unique product page copy on a phased basis.
For other common ecommerce SEO issues, check out our guides to Shopify SEO and Magento SEO.
8. AI
As you’re probably already aware, AI tools are vastly popular, especially in the digital marketing space. According to Nerdy Nav, it only took ChatGPT five days to reach its first one million users since its launch and now, 25 million people use it everyday – that’s a lot of people!
Therefore, the likelihood of people asking AI tools to write content and just copying and pasting it on their website is quite high. Plus the content that AI tools return is fairly accurate (depending on what you’re writing about) so it can be tempting to use it straight off the back without any edits or tweaks.
It’s true that AI writers can return different answers for the same question, but there’s still only so many ways content can be rewritten and similar content can impact organic success.
AI tools like ChatGPT should only be used for coming up with content ideas or for learning, not generating final content to be published on the web.
How to identify duplicate content
Now that we’ve gone through the different causes of duplicate content, how do you go about identifying it?
-
- Manual inspection – you can manually check content on different pages to see if it’s similar/identical or not, but this could be time-consuming and impractical, especially if you have a large website.
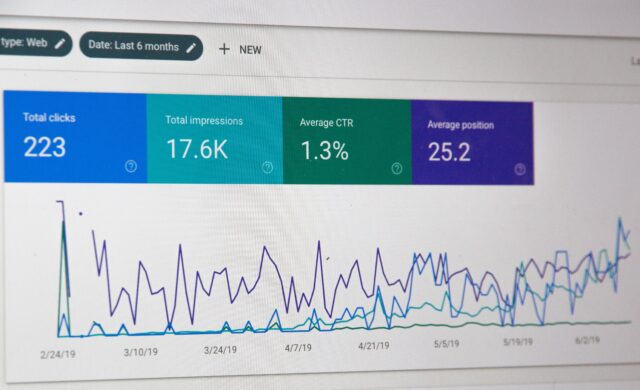
- Google Search Console – another manual check worth doing is using Search Console to look at whether the number of URLs you have indexed matches your expectations. If way more pages are indexed than you’re expecting, you may have duplicate content issues.
- Plagiarism checker – you can use online plagiarism checkers to identify duplicate content, which compare text on different web pages and highlight any similarities. My favourite is Grammarly’s as it can check for other issues like spelling, grammar, punctuation and readability.
- SEO tools – there are many SEO tools available, such as Lumar, that can help you identify duplicate content, which crawl your website and compare the content on different pages to identify any similarities.
- Technical checks – manually check different URL structures (e.g with and without www/a trailing slash). If your site uses filters, facets or appends any kind of tracking data to URLs, confirm that they all resolve correctly
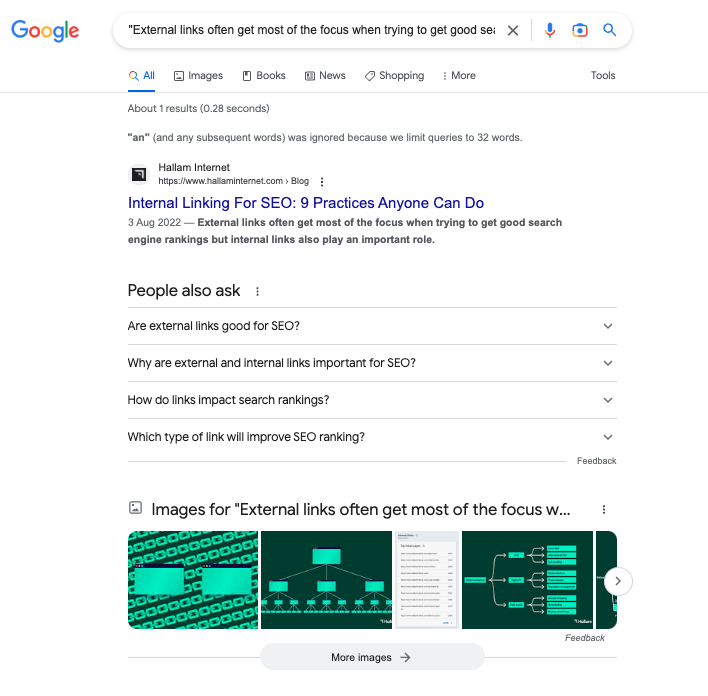
- Google search – search a sentence or a few unique phrases from your web page (use quotation marks for an exact match) and if you see other pages with the same content, it could be an indication of duplicate content. Hopefully, no one else will appear in the results!
How to fix duplicate content issues
If you have discovered some duplicate content on your website, no matter the cause, there are a few routes you could take in order to resolve it.
Use 301 redirects
If you have multiple versions of a page with the same content, you can use 301 redirects to redirect visitors and search engines to the original or preferred version of the page.
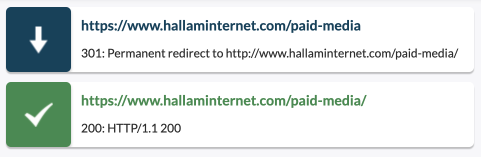
The above example is when we’ve redirected the non-slash version of our paid media page to the slash version, resolving the duplication issue. However, it’s always best practice to then find the locations of those redirects and correct them to the final destination.
Use canonical tags
Canonical tags are HTML tags that indicate to search engines which version of a page is the original or preferred one and which ones to essentially ignore. The beauty of canonical tags is that they instruct search engines on what to do, but customers can still access those pages if they need to, which may be the case for e-commerce sites.
Rewrite content
If you have multiple pages with similar or identical content, consider rewriting them to make them unique. This will help to avoid duplicate content issues and also improve the quality of your content.
Use noindex tags
If you have pages that you don’t want search engines to index, you can use the noindex tag to tell search engines not to include them in their index. This can help to avoid duplicate content issues that can arise from indexing multiple versions of the same content.
Robots.txt
Robots.txt files can be used to instruct search engines not to crawl certain URLs, which can be useful in the case of filter or query parameters.
The difference between this method and the others is that search engines won’t get as far as crawling these URLs as they’re blocked from the beginning. Whereas, redirects, canonicals and noindex tags require search engines to crawl them first.
So, blocking in robots.txt can be good for larger sites where you might want to focus on getting search engines to crawl your valuable pages and ignoring the unnecessary ones.
However, it’s worth remembering that by not crawling them, the downside is that internal and external link signals on those URLs are ignored.
Consolidate similar pages
If you have multiple pages with similar content, consider consolidating them into a single page. This can help to avoid duplicate content issues and also make the master page stronger and improve the user experience by making it easier to find relevant information on your website.
Final thoughts
In summary, duplicate content can be a problem for SEO because it can affect how websites rank on search engine results pages. It can also lead to larger issues such as decreased organic visibility and index bloat.
Fortunately, once you’ve understood what duplicate content is and what causes it, there are ways to identify and address any issues. Taking the extra time to ensure your website’s content is truly unique, genuine and authentic will be an invaluable investment in the long run.
If you need further advice or have a question, please don’t hesitate to contact us and a member of our expert SEO team will help.